Deploying a LLM server in your private cloud
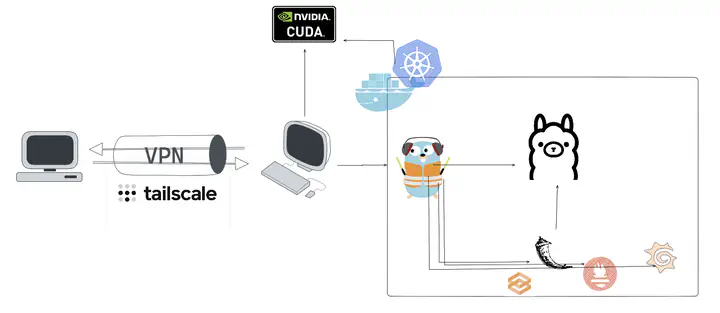
What's next?
A secure LLM server over HTTPS behind Traefik and Tailscale VPN
We'll build a robust, private network for our AI services. This setup will give us clean, secure HTTPS URLs for our internal tools without ever exposing them outside of designated VPN devices.
- LLM Inference Server: We'll use Ollama and run it in Docker Compose. Run it in k3d/k8s if you wish, though I'd consider that medium-stage where reqs include workflow parallelization with multi-node vLLMs each claiming and KV-cache-optimizing its own GPU. For now, let's say our simple PoC prefers flexible model load/unload on a single GPU, making Ollama the better tradeoff. Plus, Ollama's Golang so it's pretty darn fast too.
- Traefik: Cloud-native modern reverse proxy - adding new components to your "cloud" is as smooth as butter with yaml labels. It will act as our gateway/LB. No noisy-neighbor or security concerns to optimize for at this stage of small dev usage in VPN.
- Tailscale: Our Wireguard-based 3rd party VPN implementation. Tailscale plays well with Traefik as it will automatically append Traefik's CA to its own trusted pool, making HTTPS quite seamless (in browser.) That is, we get full browser-trusted TLS while some other pathways such as curl which don't have Tailscale in the loop may run into TLS cert errors.
Step 1: Cluster with Traefik
Traefik will be the entry point for all our services. We'll spin up a network first with it running point. Fun fact: k3d (small k8s in Docker) comes with Traefik as the reverse proxy by default. Isn't that cool?
touch docker-compose.yml traefik.yml
# docker-compose.yml
services:
traefik:
image: traefik:v3.0
container_name: traefik
command:
- "--api.insecure=true" # For the dashboard
- "--providers.docker=true"
- "--providers.docker.exposedbydefault=false"
- "--entrypoints.websecure.address=:443"
ports:
- "80:80" #http port
- "443:443" #https port
- "8080:8080" # default port for Traefik dashboard
volumes:
- /var/run/docker.sock:/var/run/docker.sock:ro
- ./letsencrypt:/letsencrypt
networks:
- internal-net
networks:
internal-net:
driver: bridge
Step 2: LLM Server with Ollama
Now, let's docker compose Ollama and be sure to append it to the current network. Then we set the labels section to instruct Docker to connect this server to Traefik.
ollama:
image: ollama/ollama
container_name: ollama
volumes:
- ./ollama:/root/.ollama
networks:
- internal-net
labels:
- "traefik.enable=true"
- "traefik.http.routers.${COMPOSE_PROJECT_NAME}_ollama.rule=Host(`you.vpn.ts.net`) && PathPrefix(`/ollama`)"
- "traefik.http.routers.${COMPOSE_PROJECT_NAME}_ollama.entrypoints=websecure"
- "traefik.http.routers.${COMPOSE_PROJECT_NAME}_ollama.tls=true"
- "traefik.http.middlewares.${COMPOSE_PROJECT_NAME}_ollama-strip.stripprefix.prefixes=/ollama"
- "traefik.http.routers.${COMPOSE_PROJECT_NAME}_ollama.middlewares=${COMPOSE_PROJECT_NAME}_ollama-strip"
- "traefik.http.services.${COMPOSE_PROJECT_NAME}_ollama.loadbalancer.server.port=11434"
Step 3: Launch and Test
Start the stack with Docker Compose.
docker compose up -d --build
Once running, you can go check out if it's working!
https://you.vpn.ts.net/ollama
# you should see: Ollama is running
https://you.vpn.ts.net/ollama/api/tags
This endpoint gives you what models this server has ready in disk.
Now, from any other device in the VPN, we can test the endpoint with curl.
curl https://you.vpn.ts.net/api/generate
-d '{
"model": "gemma3:12b",
"prompt": "Why is the sky blue?",
"stream": true
}'
If it works, you'll get a JSON response from the model, served over a secure HTTPS connection. You can hook this server url up to Gradio, or any other LCEL agentic workflows you got. You now have a working LLM server and a very rough query router - and they work.

A demo with Flask hitting up our LLM server using VPN domain