Deploying Agents with Google ADK
Developing Production-Grade Agents with Google's ADK
Moving AI agents from prototype to a production-grade system requires a methodological approach to governance, reliability, and scale. The Google Agent Development Kit (ADK) provides a framework for this engineering discipline.
This guide outlines the five key stages of the agent development lifecycle using the ADK, from initial construction to scalable deployment.

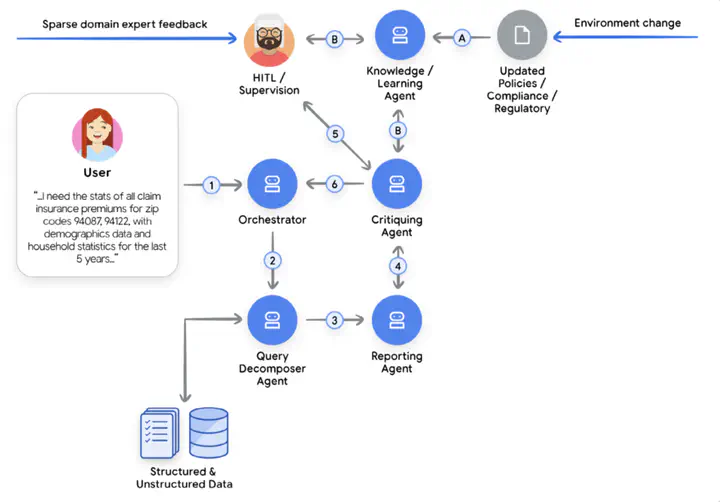
A sample agentic workflow for compliance
Step 1: Foundational Agent Construction
The initial phase involves configuring the environment (e.g., API keys for Gemini) and instantiating a single agent. This is accomplished by defining an `Agent` class with its core properties: the `model` (e.g., Gemini), an `instruction` (the system prompt), and a list of available `tools` (such as `Google Search`). The agent is executed using an `InMemoryRunner`, which orchestrates the prompt, the agent's reasoning, and the invocation of tools to generate a response.
- Whitepaper: Introduction to Agents
Step 2: Implementing Tools and Interoperability
This stage introduces two advanced patterns for agent tools. The first is the Model Context Protocol (MCP), an open standard for interoperability. Instead of writing custom API clients, an agent uses an `McpToolset` to connect to an external MCP server (e.g., for GitHub or Kaggle), which standardizes access to its available tools.
The second pattern is Long-Running Operations (LROs), which are critical for human-in-the-loop (HITL) workflows, such as requiring approval before a costly action. This is implemented by injecting a `ToolContext` into the tool function. The function calls `tool_context.request_confirmation()` to pause the agent's execution and signal for external input.
To manage the pause, the agent must be wrapped in a resumable
`App` with `ResumabilityConfig`. The
application's `Runner` is then responsible for detecting
the adk_request_confirmation event, awaiting the human
decision, and resuming the workflow by passing the approval and the original
`invocation_id` back to the runner.
Step 3: Context Engineering for Statefulness
Context engineering is implemented by distinguishing between two components: `Sessions` for short-term, single-conversation history, and `Memory` for long-term, persistent knowledge across conversations. A `MemoryService` (e.g., `InMemoryMemoryService` for development or `VertexAiMemoryBankService` for production) is provided to the `Runner` alongside the `SessionService`.
This enables two core processes. First, ingestion, where session data is explicitly persisted to the long-term store using `memory_service.add_session_to_memory()`. Second, retrieval, where the agent uses built-in tools like `load_memory` (reactive search) or `preload_memory` (proactive search) to query this knowledge. The ingestion step can be automated by using `after_agent_callback` to persist the session after every turn. Production-grade services also perform memory consolidation, extracting key facts from raw logs.
- Whitepaper: Context Engineering: Sessions & Memory
Step 4: Agent Quality and Observability

Plugins and callbacks and how they integrate into ADK runners
Ensuring production-grade reliability involves two disciplines: reactive observability (debugging what went wrong) and proactive agent evaluation (catching failures before they happen).
Observability with Plugins and Callbacks
Unlike traditional software, agents can fail mysteriously. Observability provides visibility into the agent's internal decision-making process through logs, traces, and metrics. For local debugging, the ADK Web UI (run with `adk web --log_level DEBUG`) offers a detailed, real-time view of LLM prompts and tool calls.
For automated or production environments, this logic is captured using Plugins. A Plugin is a module that hooks into the agent's lifecycle using specific Callbacks (e.g., `before_agent_callback`, `after_tool_callback`, `on_model_error_callback`). These callbacks can execute custom code, such as logging, at critical points.
Instead of building this from scratch, the ADK provides a built-in `LoggingPlugin`. By registering this plugin with the `Runner`, all agent activity—user messages, LLM requests, tool calls, and errors—is automatically logged, providing a complete execution trace for production monitoring.
Agent Evaluation
While observability is reactive, Agent Evaluation provides a proactive approach to identify quality degradations. This is essential because agents are non-deterministic and must be assessed beyond simple "happy path" tests.
The evaluation process involves running a set of test cases defined in an `*.evalset.json` file, which contains the user prompt, the expected final response, and the expected tool-call trajectory (including parameters). The `adk eval` CLI command executes these tests and compares the agent's actual output against these expectations.
Pass/fail thresholds are set in a `test_config.json` file, which defines criteria for two key metrics: the Response Match Score (text similarity of the final answer) and the Tool Trajectory Score (correctness of tool calls and arguments). This systematic regression testing catches deviations in both functional behavior and response quality. More advanced testing can use User Simulation, where an LLM dynamically generates prompts to test agent robustness.
- Whitepaper: Agent Observability & Logging
- Whitepaper: Agent Quality
Step 5: Productionization and Deployment
The final stage, productionization, is facilitated by the Agent2Agent (A2A) Protocol, an open standard for multi-agent collaboration. This is ideal for systems that cross network, language, or organizational boundaries. An ADK agent can be exposed as a service using the `to_a2a()` function, which wraps it in a server and auto-generates an `agent card`. This JSON document, served at a well-known path, acts as a formal contract by describing the agent's capabilities (skills) and endpoints.
Conversely, a remote agent can be consumed by using the `RemoteA2aAgent` class. This client-side proxy reads the remote agent's card and makes it available as a local sub-agent. ADK transparently handles all protocol-level communication (e.g., HTTP POSTs to task endpoints), allowing for complex, heterogeneous systems to be built from specialized, independent agents. The system can then be deployed to a scalable platform like Vertex AI Agent Engine.
- Whitepaper: Prototype to Production